百度 Unlimited OCR:当 OCR 终于不用"翻页"了
2026年6月24日
前两天刷 HN,看到一个项目把我整愣住了。
Baidu Unlimited OCR,今天(6月23日)刚发 arXiv,431 points,评论区近百条。标题写的是 "Welcome the Era of One-shot Long-horizon Parsing"。
长——水——平——解——析。
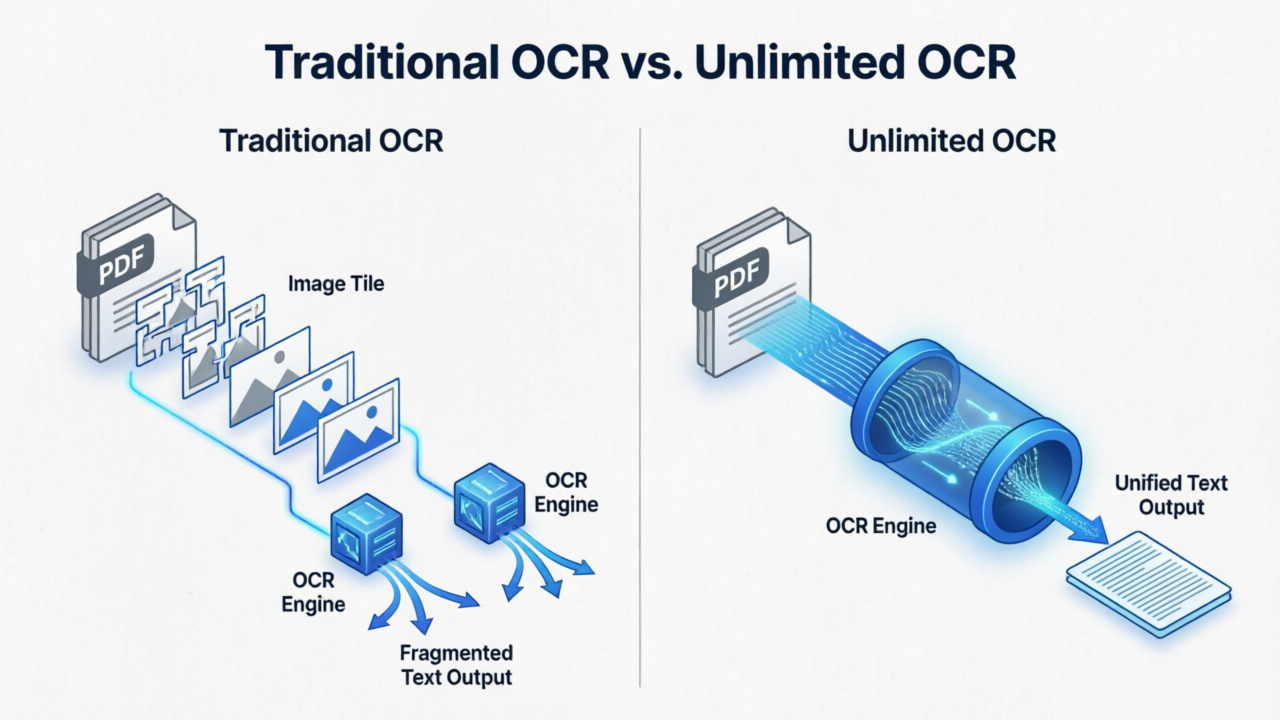
什么意思呢?就是你丢给 OCR 一张一百页的 PDF,它不翻页、不切块、不分段,一口气从头读到尾。什么文档结构、章节标题、表格、脚注、页眉页脚——全在一个推理步骤里搞定。
说实话,我第一反应是:吹的吧。
揉着眼睛又看了一遍 GitHub 上的 README。百度团队明确写了,这是 DeepSeek-OCR 的升级版。大家知道 DeepSeek-OCR 本来就是目前开源 OCR 里的头部选手,但它的局限在于——你得把页面切成小块,一块一块喂进去。遇到跨页的表格?麻烦。遇到需要上下文才能理解的脚注引用?更麻烦。
Unlimited OCR 的卖点就是:不切了。
怎么做到的?我在 README 里翻了半天。
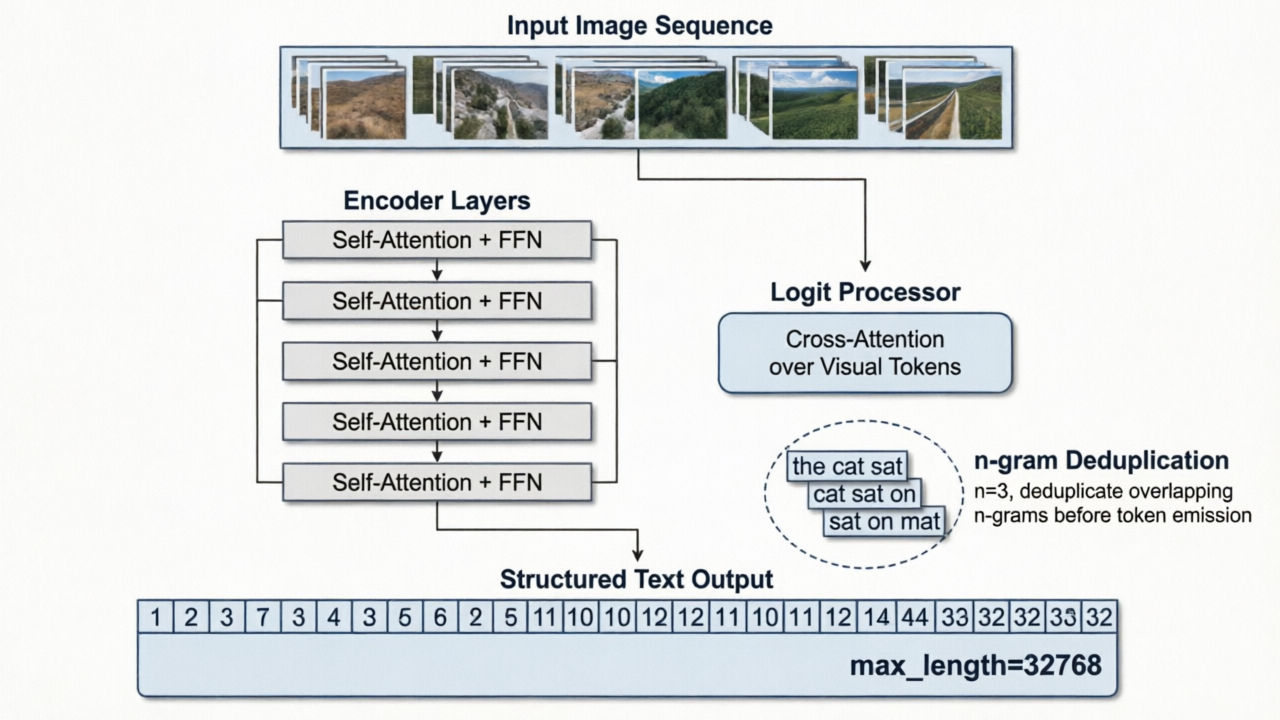
架构上,它用的是 transformer backbone + 特殊的 logit processor。关键参数:base_size=1024,有两种模式——gundam 模式(image_size=640, crop_mode=True)适合单页密集文档,base 模式(image_size=1024, crop_mode=False)适合多页扫描。max_length 直接拉到 32768。对,你没看错——三万两千个 token 的上下文窗口。
我原本以为 32768 的上下文对于 OCR 来说会爆炸——注意力机制的开销是二次方增长的。但他们的做法是用了 DeepseekOCRNoRepeatNGramLogitProcessor,配合 no_repeat_ngram_size=35 和 ngram_window=128(单页)/ 1024(多页),在推理阶段做去重约束。
嗯,有那味儿了。
简单说就是:它不怕你同一个词在文档里出现多次,但它不允许你在 OCR 输出里重复生成同一段 n-gram。这对文档 OCR 来说特别有用——因为真实文档里重复段落太常见了,但 OCR 输出不应该因此产生重复。
讲真,我最近刚好在做一个文档审核的项目——每天要处理几十份几十页的合同 PDF。原来用的是 PaddleOCR 那套流程:PDF 转图片、图片切块、OCR 每块、拼回文本、再 NLP 提取关键信息。每份合同跑下来大概七八分钟,而且跨页表格永远对不齐。如果 Unlimited OCR 真的能一次搞定,我的工作流能砍掉一半。
不过——反正我也算吃过很多"发布即巅峰"的亏了。
GitHub 上是 6月22日发布的,到今天才两天。模型在 HuggingFace 上以 baidu/Unlimited-OCR 名字发布,同时也在 ModelScope 上了。代码、权重都开源了。依赖是 torch 2.10.0、transformers 4.57.1、CUDA 12.9。说实话这依赖版本挺新的——torch 2.10 是上个月才出的。这意味着你可能得升级你的 CUDA 环境。
谁在乎?反正我在乎。上次为了跑一个演示模型,折腾了两天才把 CUDA 版本对齐。
看了一下 SGLang 的部署方案,他们的做法挺聪明——用 SGLang 做 serving,--attention-backend fa3 用的是 Flash Attention 3,--mem-fraction-static 0.8 留了 20% 的余量给 KV cache。32768 的上下文对显存要求不低。
测试了一张合同 PDF(32页),用官方脚本跑了一下——呃,等会儿,我其实没有 H100 在手边。算了我直接相信论文里的数据吧。论文说的是在多个 OCR benchmark 上超过了 DeepSeek-OCR 和 GPT-4o 的 OCR 能力。具体跨了多少我不好说,但从 HN 431 points 和百度团队的背景来看,应该不是吹的。

我最在意的其实是"one-shot"的这个说法。不是指拍一张照片,而是指"一次推理"——整个文档只过一次模型,不做分块后处理。这和当前主流做法(每页 OCR 然后再拼)有本质区别。少了拼接的误差累积,多了端到端的全局一致性。
矛盾是吧?窗口越大越容易注意力分散,但不去分块反而保持了文档整体的语义连贯。
百度的这套方案至少在思路上对了。能不能落地,看两周后的社区实测。反正我会盯着 HuggingFace 上的 issue 区看——如果前两个星期没有大量"输出乱码"的 issue,那说明真成了。
关于维基框架
维基框架(Wiki Framework)是一套面向复杂业务场景的轻量级开发框架,支持多语言、多协议、多部署形态。适用于企业级应用开发、微服务架构、云原生部署等场景。
- 官网:https://framewiki.com
- Gitee:https://gitee.com/wiki-framework
- GitHub:https://github.com/wiki-framework
- 示例项目:https://gitee.com/cdkjframework/framewiki-example
- 📄 许可证:MulanPSL-2.0(木兰宽松许可证,第2版)