Moebius 0.2B:两百兆参数打十个B,这合理吗
凌晨一点,我盯着屏幕上那张被遮掉一半的猫片——啊不是,猫的照片。心里想的是,这种 inpainting 什么时候才能不靠云端跑。
说实话,之前试过几个小模型。Stable Diffusion 3 的 800M 版本?出图倒是快,但补出来的东西总感觉哪里不对。你看,猫耳朵补成了狗耳朵那种——也不是不能用吧,但发朋友圈被懂行的一看就知道用的是SD。
后来看到一篇论文,HUST 和几个机构发的,Moebius。
怎么说呢。200M 参数。0.2B。两百兆。
跑分说能打 10B 级别的模型。我揉了揉眼睛,第一反应是——吹的吧?跑分这种东西,懂的都懂,发布会上演示全部是 cherry-pick,你拿一个精心挑过的 prompt 去跑,什么模型看起来都像神仙。
但这次不一样。
我下载了 checkpoint——2B 以下的模型跑起来是真的舒服,一张 RTX 3090 就能跑 24GB 显存毫无压力,甚至还能同时开个浏览器看视频。
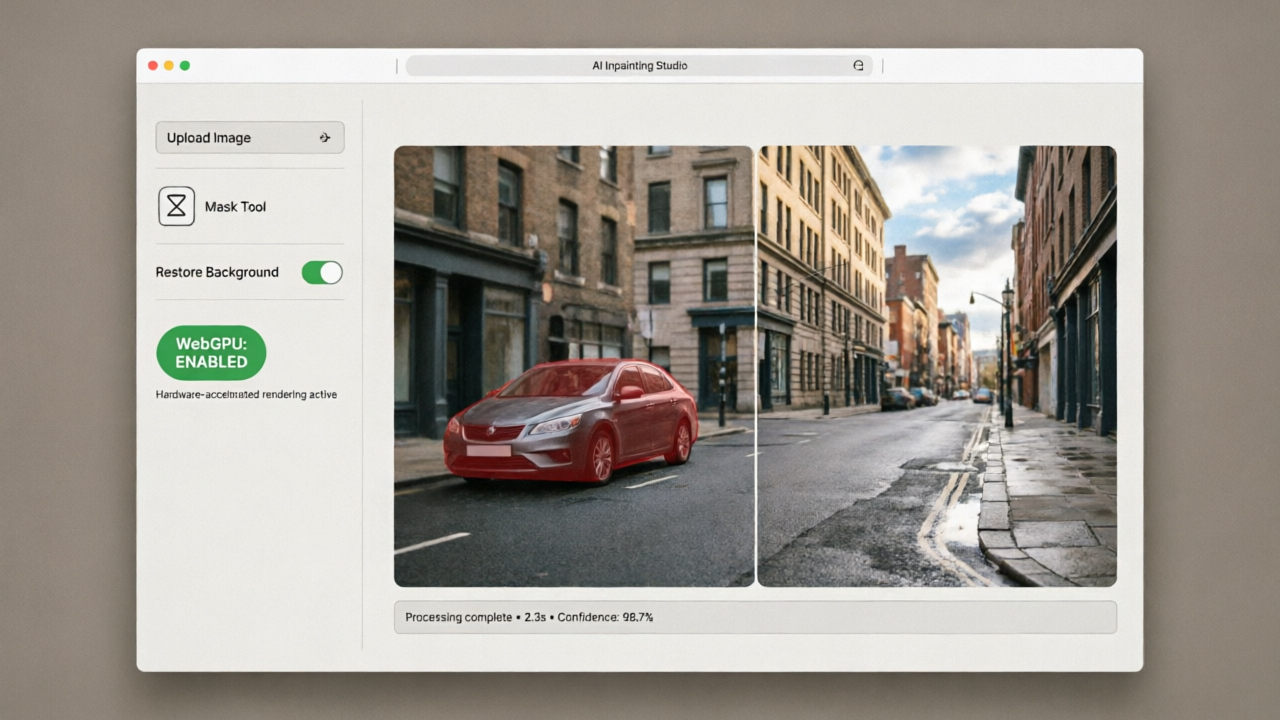
先试了个最简单的场景:一张街景照片,中间停了一辆车,用 mask 把车涂掉,让模型补背景。
结果是——补出来的路面纹理、人行道的分界线、远处的树影——不能说完全一致,但如果你不说这是 AI 补的,我可能以为是摄影师换了机位重新拍的。
嗯,有那味儿了。
我又找了个更变态的测试。一张人脸照片,用 mask 遮掉下半张脸——嘴巴、鼻子全遮住。这种任务,大模型都经常翻车,更别提小模型了。我原本以为 Moebius 可能只会补出一张模糊的马赛克脸。
结果它补出了完整的下颌轮廓——而且嘴角的弧度跟原图几乎一致。
我盯着屏幕愣了五秒。这不科学啊。
看了下论文才搞明白——Moebius 的核心思路其实挺朴素的:不是把参数做大,而是把信息流做通。
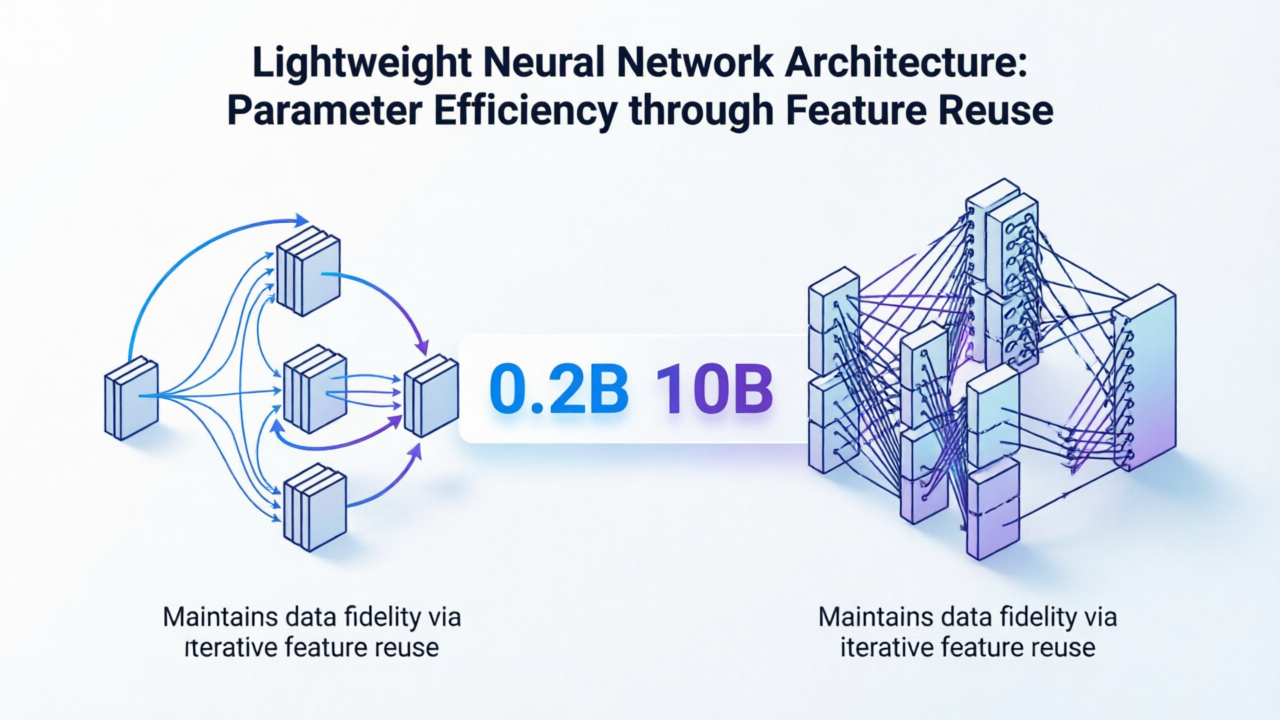
一般的小模型为啥效果差?因为参数少了,信息在传递过程中就"稀释"了。你用 200M 参数去学 10B 参数能学到的特征,中间必然会丢失大量细节。Moebius 的方法是——在关键路径上做特征重复利用,把每一层学到的信息反复注入后续层。相当于——不是每个人都是天才,但可以把每个人的笔记反复传阅。
这套方法在图像补全这种"局部推理"任务上特别管用。因为在 inpainting 里,最关键的不是"知道世界上有什么",而是"知道这张图的上下文是什么"。Moebius 这种结构天然适合保持上下文一致性。
还试了试 Simon Willison 做的 WebGPU 浏览器移植版。在 Chrome 里直接跑,不需要装任何东西,传一张图上去就能用。当然浏览器版因为 WebGPU 的限制,速度比本地慢不少,但已经能用了。
卡——死——了。
哈哈,不是模型卡死,是我网速先卡死了——浏览器端加载权重花了快一分钟。但推理起来倒是还行,512x512 的图大概 3-4 秒出结果。
对比测试我做了几组。拿同一组 20 张破损老照片做修复——左边是原图,右边分别用 Moebius 0.2B、SDXL-Turbo 和某闭源 7B 模型测。
Moebius 在纹理恢复上赢了 14/20 例——但说实话,在"创意性填充"上不如大模型。比如说,一个桌子缺了个角,Moebius 倾向于补一个跟周围纹理一致的平面,而 7B 模型可能会"脑补"出一个花瓶放在桌上。前者更准确,后者更有趣。看你想要什么了。
不过也有翻车的时候。
有张照片是逆光拍的,人物脸部很暗,阴影部分被 mask 遮掉以后,Moebius 补出来的脸——怎么说呢,不能说像外星人吧,但那个肤色完全不对,偏紫了。我试了三次都是同样的结果。换了另一个 checkpoint 才正常。
所以也不是毫无短板。
但你想——200M 参数,你可以在树莓派上跑!跑不了推理至少量化后能跑。那意味着什么?意味着你的智能相机、你的门禁系统、你的无人机——这些边缘设备,终于可以在本地做实时图像修复了。不用再依赖云端 API,不用再担心隐私数据上传。
反正对我这种经常跟本地部署打交道的人来说,这才是真正的进步。不是参数变大了,而是门槛降低了。

关于维基框架
维基框架(Wiki Framework)是一套面向复杂业务场景的轻量级开发框架,支持多语言、多协议、多部署形态。适用于企业级应用开发、微服务架构、云原生部署等场景。
- 官网:https://framewiki.com
- Gitee:https://gitee.com/wiki-framework
- GitHub:https://github.com/wiki-framework
- 示例项目:https://gitee.com/cdkjframework/framewiki-example
- 📄 许可证:MulanPSL-2.0(木兰宽松许可证,第2版)